DBT Quickstarts EP: 02

จากความเดิมตอน EP: 01 ที่เราได้มีการเกริ่นๆถึง DBT กันแล้ว วันนี้เราจะมาสอนวิธีการใช้งาน DBT เบื้องต้นกันบ้าง
Let’s start it
จุดเริ่มต้นการเรียนรู้มาจากเว็บไซต์ของพี่กานต์เลยนะครับ dbt คืออะไรนะ? (กราบบบบบบบบ 🙇🏻♂️)
โดยวิธีการ install DBT จะมีดังนี้

- Pip install DBT ลงในเครื่อง VM ตัวเอง
- Use a Docker image to install DBT
Install DBT
pip install dbt-bigquery
วิธีนี้เราสามารถลงได้ปกติเลย ด้วยคำสั่ง
pip install dbt-core #สำหรับลง DBT อย่างเดียวแบบไม่มี Database
pip install dbt-postgres #สำหรับลง DBT โดยใช้ Database คือ postgres
pip install dbt-redshift #สำหรับลง DBT โดยใช้ Database คือ redshift
pip install dbt-snowflake #สำหรับลง DBT โดยใช้ Database คือ snowflake
pip install dbt-bigquery #สำหรับลง DBT โดยใช้ Database คือ bigquery
pip install dbt-trino #สำหรับลง DBT โดยใช้ Database คือ trinoโดยในที่นี้ผมเลือก Database เป็น Bigquery เนื่องจากอยากจะพาไปดู Script ข้างหลังว่า DBT มีการรันอะไรบ้าง pip install dbt-bigquery
Use a Docker image to install DBT
วิธีนี้เป็นการรันเครื่อง VM ภายใน Docker ขึ้นมา หลังจากนั้นก็ทำการ Install ปกติได้เลย
วิธีนี้ขอแปะไว้ก่อนนะครับ พอดีเขียนเอาไว้ใช้กับ airflow แล้ว แต่ขอเป็น EP หลังๆ 🙆🏻♂️
Setup DBT
dbt init <project_name>
เป็นการสร้าง Project ขึ้นมาด้วยคำสั่ง dbt init <project_name> ซึ่งเราสามารถใส่ชื่อ project ของเราได้เลยใน project_name

project_name เป็น dbt_for_testหลังจากนั้นให้เราทำการ cat ~/.dbt/profiles.yml เพื่อดูว่าตอนนี้ DBT ของเราเชื่อมกับ database ตัวไหน

ซึ่งเป้าหมายของเราคือ เชื่อมต่อกับ bigquery ดังนั้น ให้เราทำการเปลี่ยน profile.yml ของเรา ตาม link นี้ได้เลย
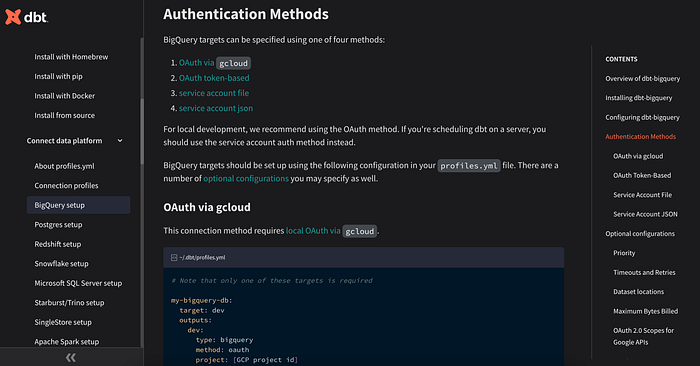
ซึ่งวิธีที่ผมเลือก คือ วิธีที่ 3 โดยการใช้ service account file เชื่อมต่อกับ Bigquery โดยผ่านไฟล์ที่อยู่ใน path keyfile : Users/aumtt/Documents/Sandbox/dbt_for_test/keyfile/playaround-sandbox-6e686317e529.json
- project (project id ของ GCP) :
playaround-sandbox - dataset (dataset บน Bigquery) :
datalake_dbt_for_test
dbt_for_test:
outputs:
dev:
type: bigquery
method: service-account
priority: interactive
keyfile: /Users/aumtt/Documents/Sandbox/dbt_for_test/keyfile/playaround-sandbox-6e686317e529.json
project: playaround-sandbox
dataset: datalake_dbt_for_test
target: dev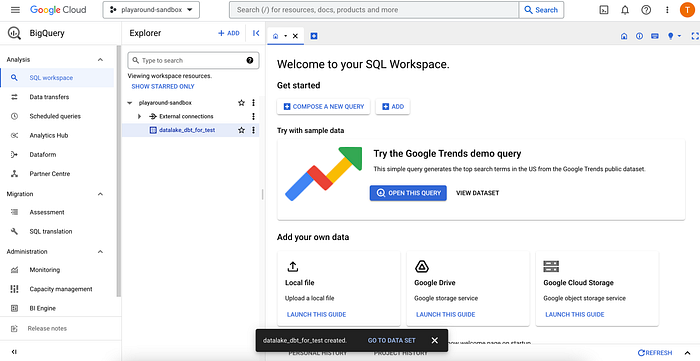
ซึ่งถ้าอยากรู้ว่าเชื่อมต่อสำเร็จหรือไม่ ให้ทำการรัน dbt debug
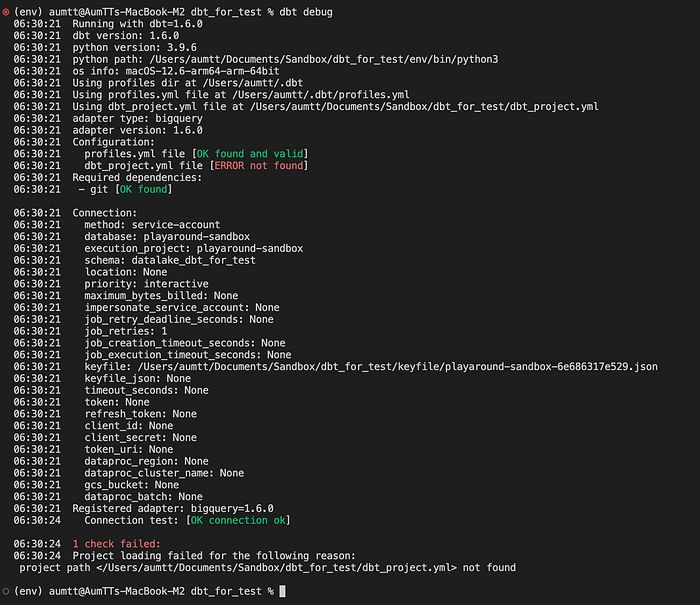
project ก่อน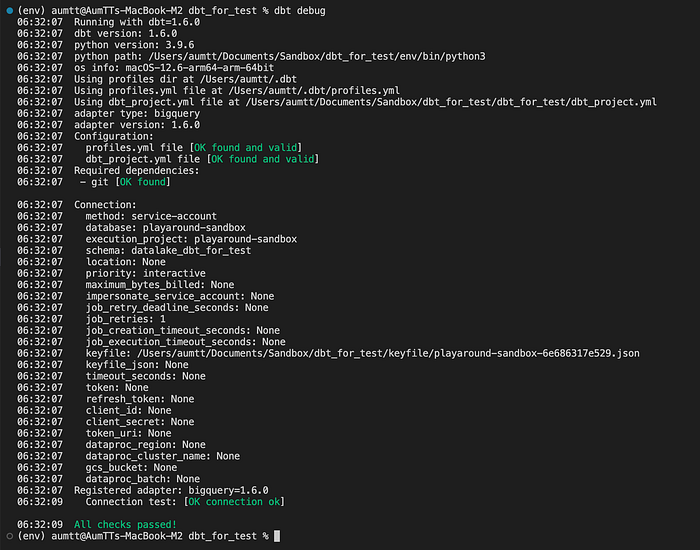
DBT seed
นำเข้ามูลที่เรามีอยู่แล้วบนเครื่อง server/VM เข้า Bigquery
ซึ่งโดยปกติแล้ว เราสามารถทำได้โดยการเข้าไปใน Bigquery UI แล้วทำการ upload ไฟล์, ตั้งชื่อ Table แล้วกดสร้าง
แต่เราสามารถย่นเวลาได้โดยการนำไฟล์ที่เรามี เข้าไปใน folder ที่ชื่อ seeds แล้วทำการรัน dbt seed ซึ่ง data ที่เรามีก็จะเข้าไปใน Bigquery ให้ตาม dataset ที่เราตั้งไว้ใน profile.yml
# โหลดไฟล์ CSV แล้วนำเข้าไปยัง folder seeds
# สัดส่วนการใช้บริการระบบขนส่งสาธารณะในกรุงเทพฯ และปริมณฑล
# https://data.go.th/dataset/otp_65_02
curl https://otp.gdcatalog.go.th/dataset/5886960e-b215-431d-94a4-65ce4ed5f1cc/resource/a0b29e78-3474-4aa1-a8a2-f98dc0565bfa/download/otp_65_02.csv -o seeds/otp_65_02.csv;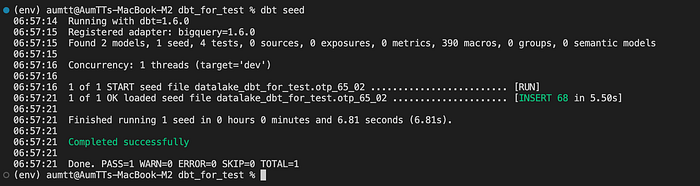
DBT model
dbt run --select sum_otp
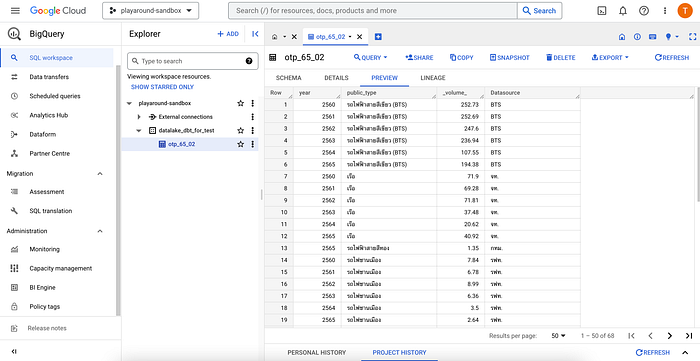
สมมุติอยากได้ table ที่หน้าตาแบบนี้ โดยสร้างอยู่ใน dataset ที่ชื่อ datamart_dbt_for_test
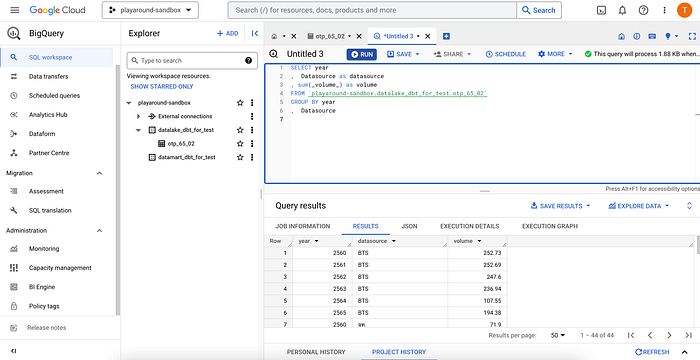
ให้เราทำการสร้าง file_name.sql ใน folder model โดยที่ file_name จะเป็นชื่อ table ใน Bigquery
โดยในที่นี้ผมใช้ sum_otp.sql (เราสามารถสร้าง folder เพื่อแยก model ของเราได้ ดังภาพข้างล่าง)
SELECT year
, Datasource as datasource
, sum(_volume_) as volume
FROM `playaround-sandbox.datalake_dbt_for_test.otp_65_02`
GROUP BY year
, Datasource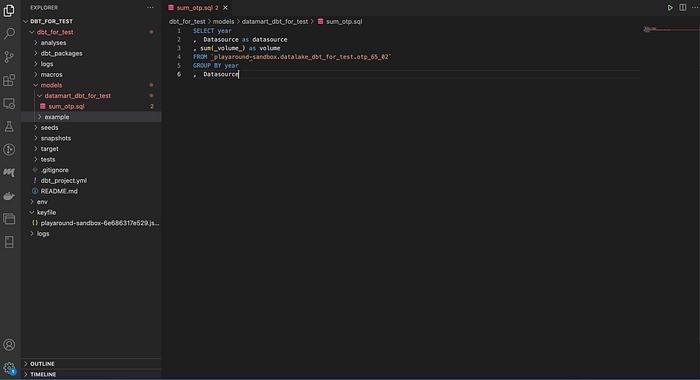
หลังจากนั้นให้เราทำการรัน model ด้วยคำสั่ง dbt run
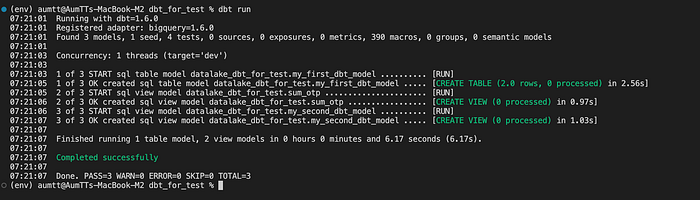
ซึ่งผมขอเพิ่มข้อสังเกตไว้แบบนี้
- มี table ทั้งหมด 3 table/view เพราะมี file example อยู่ด้วย
=> เราอยากได้เฉพาะ Table ที่เราต้องการ - Model ที่เราทำการสร้างไว้ชื่อ
sum_otpอยู่ใน dataset ที่ชื่อdatalake_dbt_for_test
=> เราอยากให้อยู่ใน dataset ที่ชื่อdatamart_dbt_for_test - Model ที่เราทำการสร้างไว้ชื่อ
sum_otpเป็น View Table
=> เราอยากให้เป็น Table แทน view
ซึ่งเราจะมาช่วยกันแก้ไขไปที่ละข้อครับ
- สามารถแก้ได้ด้วยการรัน dbt run — select ตามด้วยชื่อ model ที่อยากได้
dbt run --select sum_otp
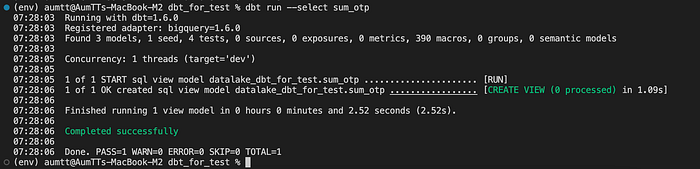
dbt run --select sum_otp2. — 3. สามารถแก้ไขได้ด้วยการเพิ่ม config ใน file model.sql
{{
config(
schema="datamart_dbt_for_test",
materialized="table"
)
}}
SELECT year
, Datasource as datasource
, sum(_volume_) as volume
FROM `playaround-sandbox.datalake_dbt_for_test.otp_65_02`
GROUP BY year
, Datasource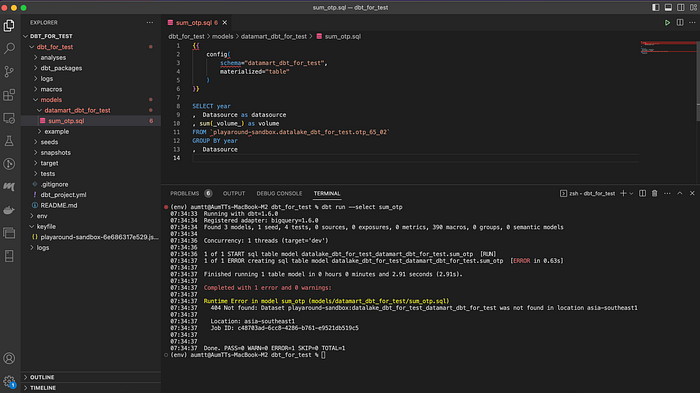
dbt run --select sum_otpแต่เมื่อรันแล้วพบ Error : 404 Not found: Dataset playaround-sandbox:datalake_dbt_for_test_datamart_dbt_for_test was not found in location asia-southeast1 และถ้าไปดูใน Bigquery จะพบว่ามีการ Create Dataset ขึ้นมา ที่ชื่อ datalake_dbt_for_test_datamart_dbt_for_test
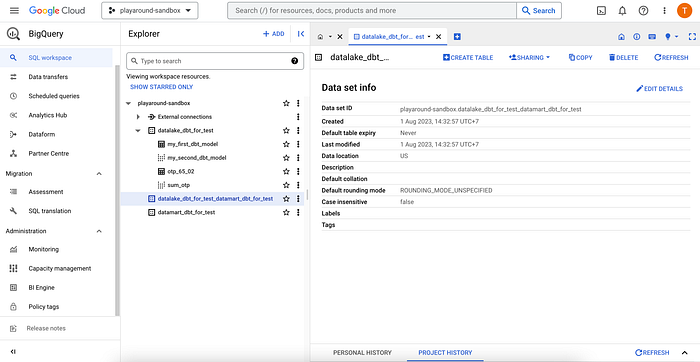
datalake_dbt_for_test_datamart_dbt_for_testซึ่งเกิดจากสาเหตุที่ว่า DBT มีการ config ไว้ว่า ถ้ามีการใส่ config ใน model.sql ให้ทำการเลือก dataset ที่เราใส่ไว้ใน profile + dataset ที่เราใส่ไว้ใน config = datalake_dbt_for_test + datamart_dbt_for_test
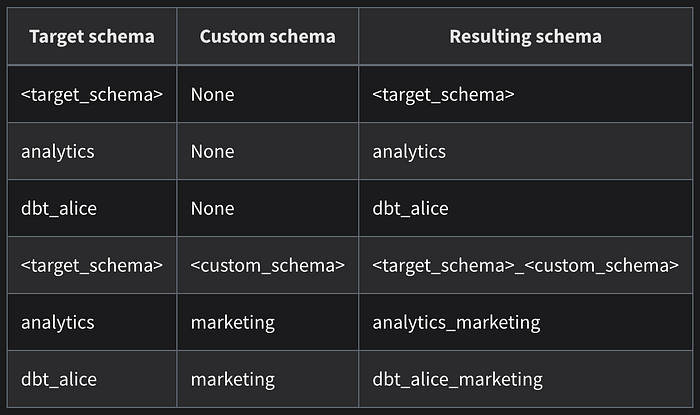
โดยถ้าเราอยากได้แค่เฉพาะ datamart_dbt_for_test ให้เราทำการเพิ่ม file.sql ใน folder macro ดังตัวอย่างที่ DBT มีการบอกไว้ (dbt_for_test/macros/generate_schema_name.sql) โดยเปลี่ยนตรง else ให้เป็นเฉพาะ custom_schema_name
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}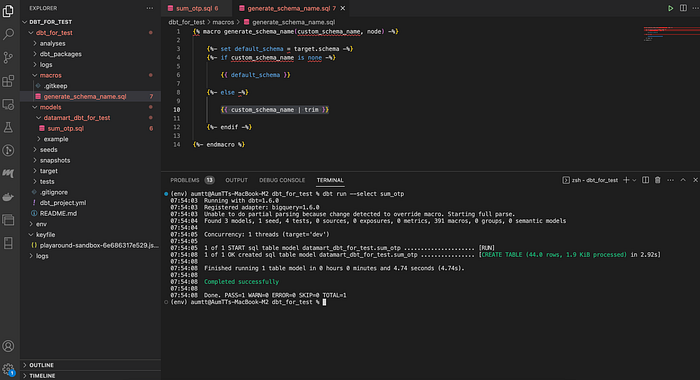
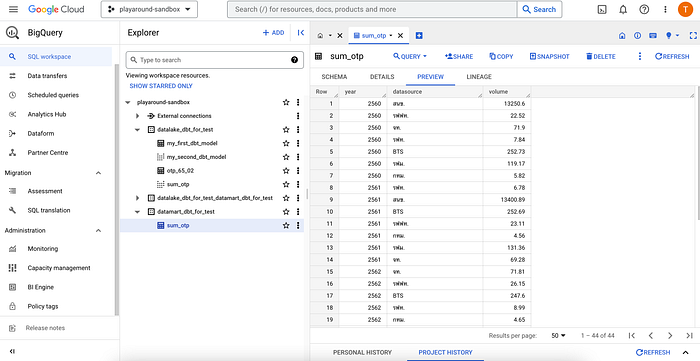
ผลลัพธ์ก็จะได้ตามที่เราต้องการแล้ว เย้ๆ 🥳
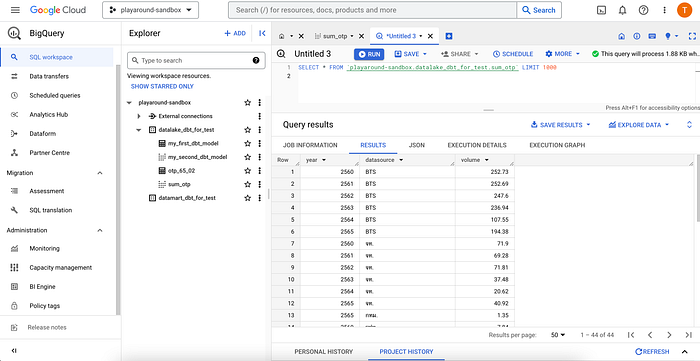
ซึ่งเราสามารถดูได้ว่า DBT รันอะไรบ้างโดยการกด Project History แล้วกด Query ล่าสุด ก็จะเห็น Query ที่ DBT ทำการรัน
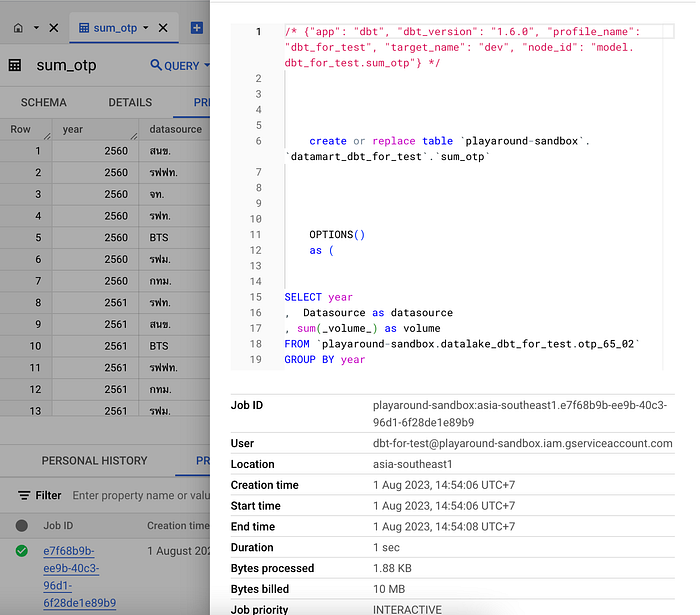
ปิดท้าย
เป็นไงกันบ้างครับการใช้งาน DBT วุ่นวายนิดหน่อย แต่ในอนาคตใช้ได้คล่องแน่นอน EP ต่อๆไป จะเริ่มยากขึ้นเรื่อยๆนะครับ ผมอยากให้ทุกคนทำความเข้าใจให้ดีๆ
แล้วเจอกันใหม่ใน EP หน้านะครับ สำหรับ EP นี้ขอบคุณมากครับ (Ps. Small Bye)
